
Essential Database Indexing Strategies for Scalable Product Development
How to improve performance, scalability, and UX by choosing the right index types.

Modern applications, from SaaS platforms to e-commerce sites, live and die by performance. As teams scale their features, users, and datasets, the speed of data access becomes a key bottleneck—or a silent superpower.
One of the most overlooked tools in your performance toolbox? Database indexes.
Whether you're a backend engineer building complex queries, or a product manager working on real-time dashboards or filters, understanding indexing is essential for delivering fast, scalable, and cost-effective systems.
Why Indexing Matters
A good index can reduce query time from seconds to milliseconds, drastically cutting load times, boosting UX, and lowering infrastructure costs. Indexes help:
Accelerate reads for common queries
Enable filters, joins, and lookups without full table scans
Reduce CPU usage and disk I/O (especially in cloud-hosted databases)
Unlock features like autocomplete, dashboards, and audit logs at scale
Analogy: Think of an index like a book's table of contents. Without it, you’d flip page by page. With it, you jump straight to what you need. Databases work the same way.
The Core Index Types
Let’s break down the three most common index types and where each shines.
1. Primary Index
What it is: Automatically created when you define a primary key. Guarantees uniqueness and powers fast direct lookups.
Use cases:
Authenticating users by email or ID
Fetching a transaction by unique order ID
Caching systems with key-based retrieval
Best practices:
Keep primary keys short (fewer bytes = faster)
Avoid volatile fields (like names or emails) as primary keys
Always prefer ID-based lookups in queries and APIs
⚙️ Backend tip: Make user IDs your query anchor. Avoid filtering on name or email unless indexed separately.
2. Clustered Index
What it is: Defines the physical sort order of rows on disk. Only one clustered index is allowed per table.
Use cases:
Fetching records within a date range (
created_at)Paginated feeds (e.g., newest posts first)
Time-series queries or log aggregations
Best practices:
Choose a column often used in range filters
Avoid indexing columns with frequent updates
Monitor fragmentation in write-heavy tables
💡 Product insight: Sorting dashboards or feeds by date? Clustered indexes can cut load times dramatically.
3. Secondary (Non-Clustered) Index
What it is: A separate structure mapping column values to row pointers. Doesn’t change physical row order.
Use cases:
Search filters: category, brand, price
Joins using foreign keys (
user_id)Autocomplete or search suggestions
Best practices:
Index columns used in
WHERE,JOIN, andORDER BYUse covering indexes to avoid extra lookups
Avoid indexing every column—it slows writes and inflates storage
For multi-column filters, use compound indexes in proper order
sql
-- Speeds up queries like:
-- SELECT * FROM products WHERE category = 'Shoes' AND price < 100; CREATE INDEX idx_category_price ON products (category, price);Advanced Index Types
Sometimes your product needs more than standard indexes. Here's what to reach for:
Full-Text Indexes
Use for: Search boxes, blogs, customer support content
Supports: Stemming, ranking, boolean operators
Available in: PostgreSQL (
tsvector), MySQL (FULLTEXT), ElasticSearch
Bitmap Indexes
Best for: Low-cardinality columns (e.g.,
is_active,gender)Use in: OLAP and reporting-heavy systems
Benefit: Compact and efficient filtering
Spatial & GIN Indexes (PostgreSQL)
Use for: Geolocation queries, JSONB fields, array containment
Ideal for: Mapping apps, analytics dashboards, metadata-heavy schemas
Indexing is only useful when it matches how your data is queried. Let usage drive design—not guesswork.
The Impact of Good Indexing
Performance Gains
Reduce query latency 10x–100x
Eliminate full table scans
Speed up dashboards, APIs, and search endpoints
Lower Infrastructure Costs
Decrease CPU usage and I/O overhead
Optimize for usage-based cloud billing (AWS RDS, GCP SQL, etc.)
Better Observability
Log user behavior with indexed timestamps or event types
Run real-time analytics on experiment flags or feature usage
Common Indexing Pitfalls

How to Choose the Right Index
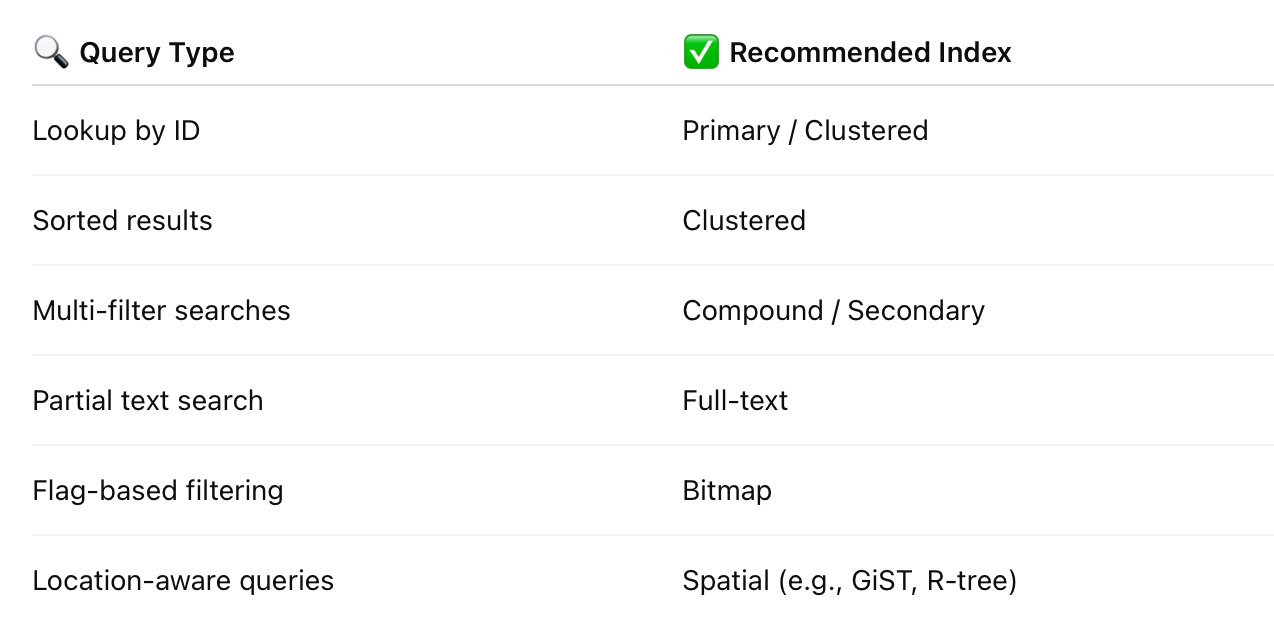
Best Practices for Product & Engineering Teams
Log slow queries and use
EXPLAINto find bottlenecksIndex real user workflows, not just developer assumptions
Track index usage and drop unused ones regularly
Balance read speed with write cost
Index logs, events, and features you want to measure
Prioritize performance-critical paths (e.g., homepage feed, search)
Helpful Tools
PostgreSQL
EXPLAIN ANALYZEpg_stat_user_indexes
MySQL
EXPLAIN FORMAT=JSONSHOW INDEXES
MongoDB
db.collection.explain()getIndexes()
Cloud-native
AWS RDS Performance Insights
GCP Query Insights
Datadog, New Relic, or custom APM dashboards
TL;DR — Indexing Cheatsheet
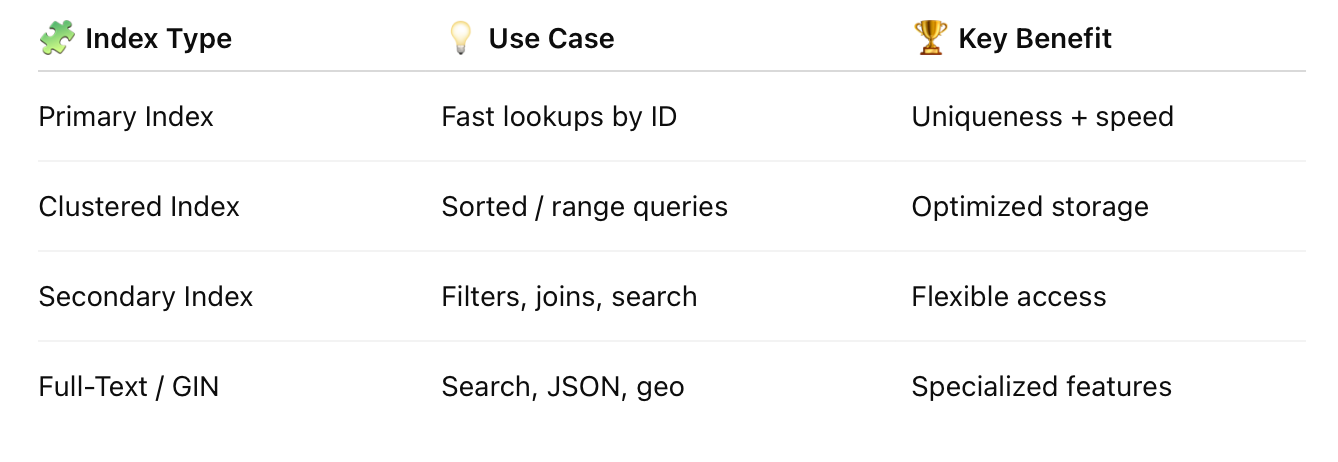
Final Thought
Smart indexing can unlock entire features: real-time filtering, fast reporting, scalable search. It also prevents future bottlenecks before they affect users or dev velocity.
If your team isn’t designing indexes proactively, you’re likely missing easy wins—and paying for it with slower UX and bloated infrastructure.
Quick favor? 👀
We wanna make our content better for you. Mind taking a super quick survey? Just a few questions to help us get to know our readers better.
Big thanks! 💛
PARTNER WITH US
Tech Scoop lands in the inboxes of 10,000+ tech leaders and engineers — the kind who build, ship, and buy.
No fluff. No noise. Just high-impact visibility in one of tech’s sharpest daily reads.
👉 Interested? Fill out this quick form to start the conversation.